
Wil je machine learning leren, maar schrikt het idee van coderen je af? Je bent niet de enige. Het goede nieuws is dat je geen programmeur hoeft te zijn om de kracht van kunstmatige intelligentie te benutten. Je hoeft alleen maar te begrijpen hoe je je gegevens kunt gebruiken om de toekomst van je bedrijf te voorspellen en slimmere en snellere beslissingen te nemen. Deze gids laat je zien hoe je ruwe gegevens kunt omzetten in een echt concurrentievoordeel, zonder ook maar één regel code aan te raken. Je leert de basisbegrippen die je nodig hebt om met technische teams te communiceren, de juiste oplossingen te beoordelen en, bovenal, te begrijpen wanneer machine learning echt het verschil kan maken voor jouw MKB-bedrijf.
Vergeet het idee dat machine learning een abstracte discipline is die voorbehouden is aan een selecte groep. Tegenwoordig is het een toegankelijk strategisch instrument dat elke sector, van de financiële wereld tot de detailhandel, ingrijpend verandert. Begrijpen hoe machines van gegevens ‘leren’ is essentieel voor iedereen die, net als jij, snellere en beter onderbouwde beslissingen wil nemen.
We zullen ons hier niet richten op ingewikkelde algoritmen, maar op resultaten die je met eigen ogen kunt zien.
Stel je een e-commerceverantwoordelijke voor die machine learning gebruikt om nauwkeurig te voorspellen welke producten het komende kwartaal als warme broodjes over de toonbank zullen gaan. Het resultaat? Een geoptimaliseerde voorraad en geen dure overtollige voorraden meer. Het rendement is direct merkbaar.
Of denk eens aan een financieel team dat dankzij een voorspellend model verdachte transacties opspoort met een 30% hogere efficiëntie dan traditionele methoden. Fraude wordt al in de kiem gesmoord, nog voordat het een probleem wordt. Dit zijn geen futuristische scenario’s, maar dagelijkse toepassingen die waarde creëren voor het bedrijf.
Het doel is duidelijk: zelfs als je niet kunt programmeren, kun je door de concepten van machine learning onder de knie te krijgen effectief communiceren met technische teams en AI-aangedreven platforms zoals Electe te beoordelen en, bovenal, gegevens om te zetten in een tastbaar concurrentievoordeel.
De groei van de sector is niet te stoppen. Wereldwijd zal de markt voor machine learning en AI tegen 2026 naar verwachting een investeringsvolume van 100 tot 120 miljard dollar bereiken, met een jaarlijkse groei van 16% tot 18%.
Deze groei wordt voornamelijk aangedreven door twee gebieden: data-engineering (35%) en kunstmatige intelligentie (31%). Voor kleine en middelgrote ondernemingen, die vaak worden geremd door een gebrek aan interne expertise, bieden data-analyseplatforms de oplossing om deze obstakels te overwinnen. Je kunt meer lezen over de ontwikkeling van deze markt op StartupItalia.

Zoals je wel kunt raden, is machine learning geen op zichzelf staand vakgebied. Het bevindt zich op het snijvlak van statistiek, datamining en kunstmatige intelligentie, met als doel waardevolle inzichten uit gegevens te halen om je besluitvorming te verbeteren.
Als je de basisprincipes van machine learning begrijpt, kun je:
Tegenwoordig is het geen keuze meer om vertrouwd te raken met de concepten van machine learning. Het is een noodzaak voor iedereen die zijn of haar bedrijf naar de toekomst wil leiden.
Voordat we ons verdiepen in de tools en de praktijk, moeten we ervoor zorgen dat we dezelfde taal spreken. Beschouw dit hoofdstuk als een woordenlijst voor de wereld van kunstmatige intelligentie, een manier om ingewikkeld klinkende begrippen te vertalen naar duidelijke ideeën die je direct in je bedrijf kunt toepassen. Het beheersen van deze basisbegrippen is de eerste, essentiële stap om machine learning op een echt strategische manier in te zetten.

Stel je voor dat je een computer wilt trainen om spam-e-mails te herkennen. Daarvoor voer je hem duizenden voorbeelden in, waarbij elk bericht al door een mens is geclassificeerd als "spam" of "geen spam". Het algoritme analyseert deze "gelabelde" gegevens en leert zelf de twee categorieën van elkaar te onderscheiden.
Kijk, dit isgeleid leren. Het model leert van een dataset waarin het juiste antwoord al is opgenomen. Het is een beetje alsof je een student een oefenboek geeft met de antwoorden achterin, om zich voor te bereiden op een examen.
Hoe wordt dit toegepast in het bedrijfsleven?
Stel je voor dat je moet voorspellen of een klant zijn abonnement zal verlengen. Het model wordt getraind met historische klantgegevens, waarbij het label 'heeft verlengd' of 'heeft niet verlengd' is. Het doel is om de opgedane kennis te gebruiken om te voorspellen wat huidige klanten zullen doen. Als je hier meer over wilt weten, ontdek dan in onze gids over voorspellende analyse hoe deze technieken gegevens kunnen omzetten in succesvolle beslissingen.
Laten we nu eens van scenario veranderen. Je hebt een berg aan gegevens over je klanten, maar deze keer zonder enige aanduiding. Je doel is om te ontdekken of er „natuurlijke” groepen bestaan, klantsegmenten met vergelijkbaar gedrag die je tot nu toe over het hoofd had gezien.
Dit isonbegeleid leren. Het model verkent de gegevens vrijelijk, zonder een „juist antwoord“ als uitgangspunt, op zoek naar verborgen patronen en groeperingen. Het is alsof je een detective een doos vol aanwijzingen geeft en hem vraagt de verbanden te ontdekken.
Hoe kun je dit toepassen in het bedrijfsleven?
Het is ideaal voor marktsegmentatie. Een clusteringalgoritme kan clusters identificeren zoals "trouwe klanten met een lage marge", "incidentele kopers van premiumproducten" of "nieuwe gebruikers met een hoog potentieel". Deze inzichten zijn van onschatbare waarde voor het personaliseren van je marketingcampagnes.
Kort gezegd geeft begeleid leren antwoord op specifieke vragen („Gaat deze klant ons verlaten?“), terwijl onbegeleid leren onverwachte inzichten aan het licht brengt („Wat voor soort klanten hebben we eigenlijk?“).
Hoe kunnen we er zeker van zijn dat een model echt heeft geleerd en niet alleen de antwoorden die we hem hebben gegeven uit het hoofd opdreunt? Simpel: we verdelen de gegevens in twee groepen.
Deze splitsing is een cruciale stap. Als het model ook op de testset goed presteert, betekent dit dat het correct heeft gegeneraliseerd en dat zijn voorspellingen voor volledig nieuwe gegevens betrouwbaar zullen zijn.
Overfitting is een van de meest voorkomende valkuilen bij machine learning. Dit gebeurt wanneer een model de trainingsgegevens te goed leert herkennen, waarbij het zelfs irrelevante details en achtergrondruis uit het hoofd leert. Het resultaat? Het model presteert uitstekend op oude gegevens, maar is totaal niet in staat om deze kennis toe te passen op nieuwe gegevens.
Het is te vergelijken met een student die de juiste antwoorden van oefentoetsen uit het hoofd leert, maar vervolgens zakt voor het echte examen omdat de vragen net iets anders zijn geformuleerd. Hij heeft het concept niet begrepen, maar alleen de voorbeelden uit het hoofd geleerd.
Een model dat aan overfitting lijdt, zou de verkoopcijfers van vorig jaar weliswaar perfect kunnen voorspellen, maar zou rampzalig slecht presteren bij het inschatten van die van het komende kwartaal.
Hier volgt een samenvatting om alles nog eens op een rijtje te zetten:
De trainingsset is het equivalent van studeren uit boeken en oefeningen: deze dient om het model te trainen op basis van historische gegevens.
De testset komt neer op het afleggen van het eindexamen: het doel ervan is om de prestaties van het model te beoordelen op basis van nieuwe gegevens die het model nog nooit eerder heeft gezien.
Overfitting is te vergelijken met het uit het hoofd leren van antwoorden: het model presteert goed op de trainingsgegevens, maar wordt onbetrouwbaar wanneer het met nieuwe situaties wordt geconfronteerd. Het herkennen en voorkomen ervan is essentieel voor het opstellen van betrouwbare voorspellingen.
AI-native platforms zoals Electe ontworpen om deze complexiteit automatisch te beheren, waarbij ze specifieke technieken gebruiken om overfitting te voorkomen en ervoor te zorgen dat de gegenereerde modellen robuust en klaar zijn voor de praktijk. Voor jou is het belangrijk om deze concepten te begrijpen. Zo kun je de resultaten kritisch interpreteren en de inzichten gebruiken om je strategieën met volledig vertrouwen te sturen. Als je het 'waarom' achter een resultaat kent, kun je beslissingen nemen die echt op data zijn gebaseerd.
Om je eerste stappen in machine learning te zetten, hoef je geen ervaren programmeur te zijn, maar als je weet welke tools er zijn en waarvoor ze dienen, heb je een enorm strategisch voordeel. Als je weet wat er ‘achter de schermen’ gebeurt, kun je de juiste oplossing voor je bedrijf kiezen en, nog belangrijker, op een deskundige manier met de technische teams communiceren.
In dit hoofdstuk zullen we een overzicht geven van de verschillende tools, beginnend bij de op code gebaseerde tools tot aan de platforms die de toegang tot AI daadwerkelijk democratiseren en het voor iedereen tot een bruikbaar hulpmiddel maken.
Ook al is het je uiteindelijke doel om geen code te hoeven schrijven, is het essentieel om de belangrijkste spelers te kennen. Python is zonder twijfel de koning onder de programmeertalen voor machine learning. Zijn populariteit is geen toeval: de taal heeft een overzichtelijke syntaxis en een ecosysteem van uiterst krachtige „bibliotheken“ die het zware werk voor je doen.
Beschouw deze bibliotheken als zeer gespecialiseerde gereedschapssets:
Je hoeft geen expert te worden in het gebruik ervan, maar als je weet dat ze bestaan en waarvoor ze dienen, kun je de technologie beter begrijpen die ten grondslag ligt aan de modernste en meest intuïtieve platforms.
De echte doorbraak voor kleine en middelgrote ondernemingen en niet-technische managers kwam met de no-code- en low-code-platforms. Deze tools bieden intuïtieve grafische interfaces waarmee complexe voorspellende analyses met slechts een paar muisklikken kunnen worden uitgevoerd, terwijl de complexiteit van de code volledig aan het oog wordt onttrokken.
No-code-platforms, zoals Electe, een door AI aangestuurd data-analyseplatform voor het MKB, zijn speciaal ontworpen voor zakelijke gebruikers. Je laadt je gegevens in, stelt het doel vast (bijvoorbeeld: "voorspel de omzet voor de komende maand") en het platform regelt de rest: van het opschonen van de gegevens tot het kiezen van het beste algoritme, tot het presenteren van de inzichten op een duidelijke en begrijpelijke manier.
Het doel van deze tools is niet om datawetenschappers te vervangen, maar om de kracht van AI rechtstreeks in handen te geven van degenen die het bedrijf door en door kennen: managers, marktanalisten en ondernemers.
Deze oplossingen nemen technische drempels en instapkosten weg, waardoor een zeer snelle implementatie en een vrijwel onmiddellijk rendement op de investering mogelijk worden.
De keuze van het instrument hangt volledig af van je doelstellingen en de mate van controle die je over het proces wilt hebben. Er is geen eenduidig antwoord, maar er is zeker een oplossing die bij elke behoefte past.
Om je te helpen je weg te vinden in het huidige aanbod, hebben we een vergelijkingstabel opgesteld waarin de belangrijkste verschillen tussen de verschillende benaderingen worden belicht, zodat je de keuze kunt maken die het beste aansluit bij je kennisniveau en je bedrijfsdoelstellingen.
Een gids om het juiste instrument te kiezen op basis van je vaardigheidsniveau en je bedrijfsdoelstellingen, van no-code tot geavanceerde bibliotheken.
No-code-platforms — zoals Electe zijn ideaal voor managers, bedrijfsanalisten en ondernemers die op zoek zijn naar snelle inzichten om strategische beslissingen te sturen. Er is geen programmeerkennis voor nodig, waardoor ze toegankelijk zijn voor iedereen die nog geen ervaring heeft. Een concreet voorbeeld is het uploaden van verkoopgegevens om binnen enkele minuten een prognose van de kwartaalomzet te krijgen.
Low-code-platforms zijn bedoeld voor analisten met enige technische kennis die modellen willen aanpassen zonder alle code helemaal zelf te schrijven. Er is een gemiddeld kennisniveau vereist, met basiskennis van SQL of scriptlogica. Een typisch voorbeeld is het bouwen van een aangepast kredietrisicomodel door enkele door het platform voorgestelde parameters aan te passen.
Python-bibliotheken — zoals Scikit-learn — zijn bedoeld voor datawetenschappers en ontwikkelaars die volledige controle nodig hebben om op maat gemaakte AI-oplossingen te bouwen. Ze vereisen een gevorderd niveau, met gedegen kennis van programmeren en statistiek. Een goed voorbeeld hiervan is het vanaf nul ontwikkelen van een productaanbevelingssysteem voor een e-commercewebsite.
Zoals je ziet, is de aanpak voor het toepassen van machine learning flexibel. Als het je voornaamste doel is om tastbare bedrijfsresultaten te behalen zonder je te verliezen in de techniek, dan zijn no-code-platforms het meest logische en effectieve startpunt. Voor een meer diepgaande analyse kun je onze gids lezen over de 7 beste AI-tools voor bedrijfsgroei.
Welk instrument je ook kiest, er zijn een aantal analytische vaardigheden (die niet louter wiskundig zijn) die altijd het verschil zullen maken. Technologie is een krachtige katalysator, maar kritisch en strategisch denken blijft onvervangbaar.
De belangrijkste vaardigheden die je moet ontwikkelen zijn:
Kortom: de keuze voor het juiste instrument is de eerste stap, maar het is de combinatie van technologie en strategisch denken die een echt concurrentievoordeel oplevert.
Goed, het is tijd om de theorie in de praktijk te brengen. Tot nu toe hebben we concepten en tools verkend, maar het echte leren – het leren dat je bijblijft – begint pas als je zelf aan de slag gaat met een echt probleem. In dit deel neem ik je mee door de logica van een machine learning-project, maar met een verrassende wending: we gaan geen enkele regel code schrijven.
We gaan een praktijkvoorbeeld bekijken, een onderwerp dat voor elke kmo van cruciaal belang is: klantsegmentatie. Het doel hiervan is niet technisch, maar puur strategisch. Het gaat erom te leren denken als een datawetenschapper om gegevens om te zetten in beslissingen die uiteindelijk waarde opleveren.
De onderstaande infographic toont het vereenvoudigde traject dat we zullen volgen, vanaf de zakelijke vraag tot aan de praktische toepassing, die zowel met no-code-tools als, uiteraard, met code kan plaatsvinden.
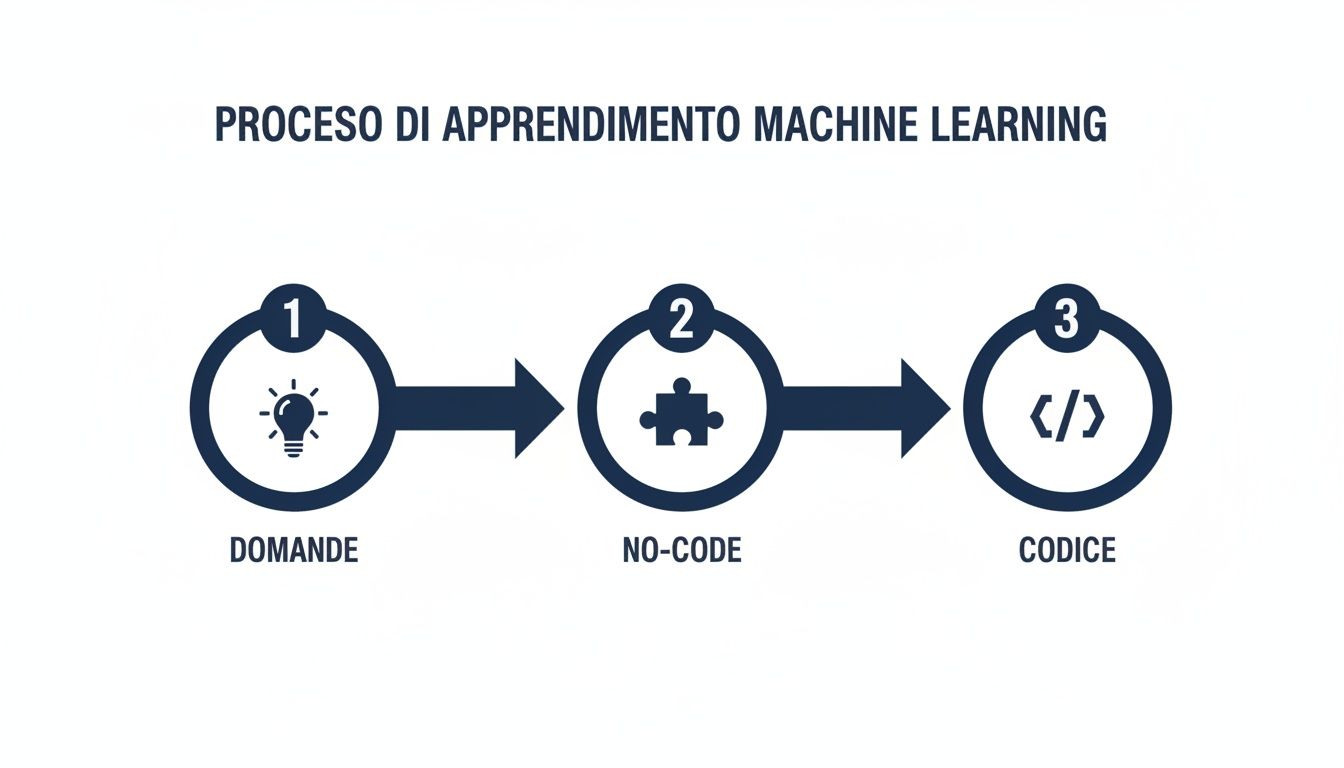
Zoals je ziet, begint alles met een goed geformuleerde zakelijke vraag. Van daaruit kun je verdergaan met meer toegankelijke oplossingen (no-code) of met technische benaderingen, afhankelijk van de middelen en doelstellingen die je voor ogen hebt.
De eerste stap bij elk analyseproject is nooit technisch, maar strategisch. We moeten een duidelijke vraag formuleren. In ons geval volstaat het niet om te zeggen: „Ik wil de klanten segmenteren.“ De echte vraag is waarom we dat willen doen.
Een duidelijk omschreven bedrijfsdoelstelling klinkt ongeveer als volgt: "Klantengroepen met vergelijkbaar koopgedrag identificeren om marketingcampagnes te personaliseren en de conversieratio in het komende kwartaal met 10% te verhogen."
Zie je het verschil? Deze definitie is krachtig omdat ze specifiek en meetbaar is en gekoppeld is aan een tastbaar bedrijfsresultaat. Ze geeft ons een duidelijke richting en een maatstaf om te beoordelen of ons project al dan niet succesvol is geweest.
Zodra het doel zwart op wit staat, is de volgende vraag: "Oké, welke gegevens hebben we nodig om hierop te kunnen reageren?". Om klanten te segmenteren op basis van hun koopgedrag, hebben we een dataset nodig die informatie bevat zoals:
Deze fase kost in de praktijk vaak de meeste tijd, maar is ook bepalend voor de kwaliteit van alles wat daarna komt. Laten we voor deze oefening aannemen dat we al een mooi, overzichtelijk bestand hebben met deze kolommen. Platformen zoals Electe zijn precies hiervoor in het leven geroepen: ze automatiseren een groot deel van het proces, maken rechtstreeks verbinding met je gegevensbronnen en maken de informatie klaar voor analyse.
Nu we een duidelijk doel voor ogen hebben en de gegevens klaar zijn, is het tijd om het model te kiezen. Aangezien het ons doel is om "verborgen" groepen te ontdekken zonder vooraf gedefinieerde labels (zoals "topklant" of "verloren klant"), bevinden we ons op het gebiedvan onbegeleid leren.
Het aangewezen instrument voor deze taak is een clusteringalgoritme, zoals het bekende K-Means. Laat je niet afschrikken door de naam; het doel ervan is verrassend eenvoudig. Het verdeelt de klanten in een aantal door ons gekozen „clusters“ (laten we zeggen 4), waarbij ervoor wordt gezorgd dat de klanten binnen elke groep zoveel mogelijk op elkaar lijken en tegelijkertijd zo verschillend mogelijk zijn van die in de andere groepen.
In een no-code-omgeving hoef je het algoritme zeker niet zelf te implementeren. Je hoeft alleen maar de gegevens te uploaden, een optie te selecteren zoals "klantsegmentatie" of "clustering" en aan te geven hoeveel groepen je wilt vinden. Het platform doet de rest.
Nu komen we bij de cruciale fase, waarin de technologie een stap opzij doet en plaats maakt voor menselijke analyse en zakelijke kennis. Het algoritme levert ons vier clusters op, maar voorlopig zijn het slechts cijfers. Het is onze taak om deze om te zetten in 'profielen' van echte klanten, met een achtergrondverhaal en behoeften.
Als we de gemiddelde kenmerken van elke cluster analyseren, zouden we profielen zoals deze kunnen ontdekken:
Dit proces zet een numerieke analyse om in een concrete en uitvoerbare marketingstrategie. We hebben de gegevens een naam en een gezicht gegeven, en zo de basis gelegd voor gerichte communicatie die elk specifiek segment echt aanspreekt. Dit is de kern van machine learning toegepast op het bedrijfsleven: het gaat niet om algoritmen, maar om het nemen van betere beslissingen.
Oké, je begrijpt nu de logica achter begeleid en onbegeleid leren. Je weet waarom overfitting een vijand is die je moet vermijden. Laten we het nu echter eens hebben over de snelle manier waarop je deze kennis kunt gebruiken om concrete bedrijfsresultaten te behalen, zonder ook maar één regel code te schrijven. Dit is waar AI-aangedreven data-analyseplatforms, zoals Electe, om de hoek komen kijken.
Zie deze tools als een brug. Aan de ene kant staan jouw zakelijke vaardigheden, aan de andere kant de kracht van machine learning. Zij zorgen ervoor dat de meest technische en complexe stappen worden geautomatiseerd, zodat jij je kunt richten op het belangrijkste: de inzichten interpreteren en betere beslissingen nemen.
Laten we teruggaan naar de voorbeelden van daarnet. Stel dat je je klanten wilt segmenteren, net zoals in de theoretische oefening. Met een no-code-platform verloopt dit proces aanzienlijk eenvoudiger en sneller. Je hoeft je geen zorgen te maken over de keuze voor het K-Means-algoritme of je hoofd te breken over de voorbereiding van de gegevens.
De werkstroom ziet er in de praktijk als volgt uit:
Hetzelfde geldt voor de verkoopprognoses. In plaats van een model helemaal zelf op te bouwen, laad je de historische gegevens in en vraag je het platform om een prognose voor het komende kwartaal. Het systeem zorgt zelf voor de verdeling tussen trainings- en testdatasets en neemt de juiste maatregelen tegen overfitting.
De kennis die je hebt opgedaan, gaat niet verloren, maar wordt juist uitgebreid. Nu je weet wat overfitting is, zul je de betrouwbaarheid van voorspellingen met een kritischer blik beoordelen. Door het verschil tussen supervised en unsupervised learning te begrijpen, zul je de juiste analyse voor het juiste probleem kiezen.
Deze aanpak zorgt vooral voor een ommekeer bij kleine en middelgrote ondernemingen. In Italië kijken KMO’s met grote belangstelling naar AI – 58% geeft aan nieuwsgierig te zijn – maar de cijfers spreken voor zich: slechts 7% van de kleine bedrijven en 15% van de middelgrote bedrijven heeft concrete projecten opgezet. Er is een enorm, onontgonnen potentieel dat platforms zoals Electe helpen ontsluiten door toegankelijke tools aan te bieden waarvoor geen teams van gespecialiseerde technici nodig zijn.
Met Electe is het leren van machine learning niet langer een technisch programmeertraject, maar een proces van strategische toepassing. Je leercurve hangt niet langer af van de code, maar van het vermogen om de juiste vragen te stellen aan je bedrijf.
Deze interface is een treffend voorbeeld: de gebruiker selecteert de variabelen voor een voorspellende analyse zonder ook maar één regel code aan te raken.
Kies gewoon het doel, bijvoorbeeld 'Verkoopprognose', en het systeem zorgt zelf voor de modellering en presenteert de resultaten op een duidelijke en visuele manier.
No-code-platforms maken geavanceerde data-analyse voor iedereen toegankelijk. Je hebt geen team van datawetenschappers meer nodig om nauwkeurige voorspellingen te doen of verborgen klantsegmenten te ontdekken. Managers, marketinganalisten en verkoopmanagers kunnen rechtstreeks met de gegevens werken, hypothesen toetsen en vrijwel direct antwoorden krijgen.
Dit versnelt niet alleen het besluitvormingsproces, maar bevordert ook een bedrijfscultuur die daadwerkelijk op data is gebaseerd. Als je de basisbegrippen van machine learning begrijpt, word je een bewustere en effectievere gebruiker van deze platforms, die in staat is om het volledige potentieel ervan te benutten om groei te stimuleren. Lees meer over hoe Electe geavanceerde technologie voor iedereen toegankelijkElecte .
Laten we eens kijken naar enkele van de meest voorkomende twijfels die mensen die voor het eerst met machine learning in aanraking komen, tegenhouden. Deze antwoorden helpen je om die aanvankelijke onzekerheden te overwinnen en je volgende stappen met meer zelfvertrouwen te plannen, waarbij je je kunt concentreren op wat echt belangrijk is voor je bedrijf.
Minder dan je denkt. Als het je doel is om de basisbegrippen te begrijpen om met technici te kunnen communiceren en intuïtieve platforms te gebruiken zoals Electete gebruiken, volstaan een paar weken gericht studeren. Je hoeft geen datawetenschapper te worden, maar wel een professional die AI strategisch kan inzetten.
Als je 5 tot 8 uur per week besteedt aan hoogwaardige inhoud, ben je binnen een maand klaar om waarde uit je gegevens te halen. De sleutel is doorzettingsvermogen en het vermogen om je te richten op zakelijke vraagstukken, niet op abstracte theorie.
Absoluut niet. Om machine learning toe te passen op bedrijfsproblemen heb je geen diploma in wiskunde of statistiek nodig. Natuurlijk helpt het als je een basiskennis hebt van begrippen als het gemiddelde of correlatie, maar moderne platforms zoals Electe al die complexiteit voor je Electe handen.
Je belangrijkste vaardigheid zal altijd die zijn die verband houdt met je vakgebied: de context begrijpen, de juiste vragen stellen en de resultaten interpreteren om beslissingen te sturen. Technologie is slechts een hulpmiddel.
Je kennis van de markt is veel waardevoller dan welke ingewikkelde formule dan ook als het erom gaat een analyse om te zetten in winstgevende actie.
Het beste project is het project dat een echt en urgent probleem voor je bedrijf oplost. Laat die algemene datasets die je online vindt maar zitten; begin met een concrete vraag die je jezelf elke dag stelt.
Enkele praktische tips:
Maak gebruik van de gegevens die je al hebt en die je door en door kent. Via platforms zoals Electe je bestanden uploaden en binnen enkele minuten antwoord krijgen op deze vragen. Zo wordt leren praktisch, snel en levert het direct resultaat op.
Dit is een veelgehoorde zorg, maar vaak gaat het om een schijnprobleem. Je hebt geen terabytes aan gegevens nodig om aan de slag te gaan. Zelfs datasets van gemiddelde omvang kunnen ongelooflijk nuttige patronen aan het licht brengen, mits je de juiste modellen en technieken gebruikt. Het belangrijkste is de kwaliteit van de gegevens, niet alleen de kwantiteit.
Een overzichtelijk en goed gestructureerd bestand met de gegevens van duizend trouwe klanten kan oneindig veel waardevoller zijn dan een miljoen rommelige en onvolledige records.
Platforms zoals Electe precies hiervoor ontworpen: om ook uit niet al te grote datasets de maximale waarde te halen. Ze kiezen automatisch de meest robuuste statistische methoden om je betrouwbare inzichten te bieden waarop je je strategieën kunt baseren, waardoor zelfs een beperkte hoeveelheid informatie kan worden omgezet in een concurrentievoordeel. Het belangrijkste is om te beginnen.
Je hebt nu een duidelijk stappenplan om je reis in de wereld van machine learning te beginnen. Voor deze reis heb je geen programmeervaardigheden nodig, maar wel nieuwsgierigheid en een strategische aanpak. Door deze basisbegrippen te begrijpen, heb je al een voorsprong opgebouwd: je ziet gegevens niet langer als een simpele verzameling getallen, maar als de meest waardevolle bron om de toekomst van je bedrijf te verhelderen.
Ben je klaar om deze kennis in daden om te zetten? Met Electekun je met een paar muisklikken de kracht van machine learning toepassen op je bedrijf, zonder ook maar één regel code te schrijven. Het is tijd om te stoppen met gissen en te beginnen met beslissingen nemen met de zekerheid die alleen data je kan bieden.

.svg)
.svg)
.svg)



.png)


