
Stel je voor dat je een computer kunt leren om verborgen zakelijke kansen in je gegevens te ontdekken, een beetje zoals je een kind leert om vormen te herkennen. Machine learning-algoritmen zijn precies dat: 'slimme instructies' waarmee computersystemen kunnen leren van gegevens zonder expliciet voor elke afzonderlijke taak te worden geprogrammeerd. In de praktijk zetten ze een zee aan informatie om in nauwkeurige voorspellingen en strategische beslissingen die uw bedrijf kunnen laten groeien.
U bent hier aan het juiste adres om te begrijpen hoe deze technologie, die vroeger voorbehouden was aan enkele grote bedrijven, vandaag de dag een toegankelijk en essentieel instrument is voor kleine en middelgrote ondernemingen die willen concurreren en winnen op de markt. In deze gids ontdekt u niet alleen wat deze algoritmen zijn, maar ook hoe u ze concreet kunt gebruiken om uw verkoop te optimaliseren, uw efficiëntie te verbeteren en beslissingen te nemen op basis van concreet bewijs.

Tegenwoordig zijn gegevens de brandstof van elk bedrijf. Maar zonder de juiste tools blijven het slechts cijfers in een spreadsheet. Hier komen machine learning-algoritmen om de hoek kijken, de echte motor achter moderne kunstmatige intelligentie. Zij zetten ruwe gegevens om in een echt concurrentievoordeel.
Deze wiskundige modellen kijken niet alleen naar het verleden, maar leren ervan om de toekomst te voorspellen. Ze identificeren patronen, correlaties en afwijkingen die een mens nooit zou kunnen opmerken, en bieden zo duidelijke inzichten om uw bedrijfsstrategie te sturen.
Voor kleine en middelgrote ondernemingen is het integreren van machine learning niet langer een optie, maar een noodzaak om concurrerend te blijven. Het doel is niet om u tot een statistiekdeskundige te maken, maar om u concrete antwoorden te geven op vragen die essentieel zijn voor uw bedrijf.
De voordelen zijn tastbaar:
Deze technologie zorgt nu al voor een ommekeer. In Italië heeft de markt voor kunstmatige intelligentie een omvang van 1,8 miljard euro bereikt, met een groei van 50% in slechts één jaar tijd. Machine learning alleen al vertegenwoordigt 54% daarvan . Dit is een duidelijk teken dat steeds meer bedrijven algoritmen gebruiken om gegevens te analyseren en hun prestaties te verbeteren. Als u meer wilt weten, lees dan meer details over hoe AI Italiaanse bedrijven transformeert.
Simpel gezegd vormen machine learning-algoritmen de brug tussen uw gegevens en uw beslissingen. Ze stellen u in staat om van 'wat is er gebeurd?' naar 'wat gaat er gebeuren?' en, nog belangrijker, naar 'wat moet u doen?' over te stappen.
AI-aangedreven platforms zoals Electe, een AI-aangedreven data-analyseplatform voor kleine en middelgrote ondernemingen, zijn juist voor dit doel ontwikkeld: om zo'n krachtige technologie toegankelijk te maken. U hebt geen team van datawetenschappers nodig om waarde uit uw gegevens te halen. Ons platform neemt de technische complexiteit voor zijn rekening, zodat u zich kunt concentreren op wat echt belangrijk is: het laten groeien van uw bedrijf.
Om je weg te vinden in de wereld van machine learning, moet je eerst begrijpen dat niet alle algoritmen hetzelfde zijn. Ze kunnen worden onderverdeeld in drie grote benaderingen, drie 'families', elk met een andere leermethode, bedoeld om totaal verschillende zakelijke problemen op te lossen.
De eenvoudigste manier om het concept te begrijpen, is door ze voor te stellen als drie soorten studenten: een die leert met een leraar (begeleid), een andere die dingen zelf ontdekt door gegevens te analyseren (onbegeleid) en een derde die leert door vallen en opstaan (versterking). Het begrijpen van dit onderscheid is de eerste stap om het juiste instrument voor uw behoeften te kiezen.
Begeleid leren is de meest voorkomende en intuïtieve benadering. Het werkt precies zoals een leerling die van een leraar leert door voorbeelden te volgen die al zijn uitgevoerd. Deze algoritmen krijgen 'gelabelde' gegevens, dat wil zeggen een set informatie waarvan het juiste antwoord al bekend is.
Stel je voor dat je een algoritme wilt leren om spam-e-mails te herkennen. Je geeft het duizenden e-mails die al handmatig zijn geclassificeerd als 'spam' of 'geen spam'. Het algoritme analyseert ze, leert de kenmerken te herkennen die de twee categorieën onderscheiden en kan, eenmaal getraind, zelf nieuwe e-mails classificeren.
Er zijn twee hoofddoelstellingen:
In tegenstelling tot het voorgaande werkt onbegeleid leren zonder begeleiding. Het is als een detective die zelf patronen en verbanden moet vinden tussen het bewijsmateriaal dat hij tot zijn beschikking heeft. Het algoritme onderzoekt vrijelijk ongemarkeerde gegevens om verborgen structuren daarin te ontdekken.
Een klassieke toepassing is de segmentatie van klanten. U kunt de aankoopgegevens van uw klanten aan het algoritme verstrekken en het zal deze zelfstandig groeperen in "clusters" op basis van vergelijkbaar gedrag, waardoor marktsegmenten worden onthuld waar u nog nooit aan had gedacht.
Onbegeleid leren blinkt uit in het beantwoorden van vragen waarvan je niet eens wist dat je ze moest stellen, en onthult zo de verborgen mogelijkheden in je gegevens.
Ten slotte is reinforcement learning gebaseerd op een systeem van beloningen en straffen. Het algoritme, dat we 'agent' noemen, leert door acties uit te voeren in een omgeving om een beloning te maximaliseren. Niemand vertelt hem wat hij moet doen, maar hij ontdekt door voortdurend te proberen en fouten te maken welke acties tot de beste resultaten leiden.
Denk aan een kunstmatige intelligentie die leert schaken. Als een zet hem een voorsprong oplevert, krijgt hij een 'beloning'. Als de zet contraproductief is, krijgt hij een 'straf'. Na miljoenen partijen leert hij de winnende strategieën. Deze aanpak is perfect voor het optimaliseren van complexe en dynamische processen, zoals realtime voorraadbeheer.
Dit gedeelte vat de belangrijkste verschillen tussen de drie benaderingen samen.
Begeleid leren vereist gelabelde gegevens en heeft als hoofddoel voorspellingen te doen of te classificeren. Een concreet voorbeeld uit het bedrijfsleven is het voorspellen van het klantverloop (churn prediction).
Onbegeleid leren werkt daarentegen met niet-gelabelde gegevens en is gericht op het ontdekken van verborgen patronen en structuren. In het bedrijfsleven is een typische toepassing het segmenteren van klanten in groepen op basis van hun koopgedrag.
Versterkend leren is gebaseerd op interactiegegevens en heeft als doel het optimaliseren van een besluitvormingsproces. Een praktisch voorbeeld hiervan is de dynamische prijsoptimalisatie van een e-commerceproduct.
Het begrijpen van deze drie families is de eerste, fundamentele stap om de kracht van machine learning-algoritmen te benutten. Met een platform als Electehoef je geen expert te zijn om ze toe te passen: ons systeem helpt je bij het kiezen van het beste model voor jouw gegevens en bedrijfsdoelstellingen, waardoor complexiteit een concurrentievoordeel wordt.
Als het gaat om machine learning in bedrijven, spelen algoritmen voor begeleid leren bijna altijd een hoofdrol. De reden hiervoor is simpel: ze bieden directe antwoorden op cruciale zakelijke vragen. Stel dat u de omzet van het komende kwartaal wilt voorspellen op basis van de verkoopgeschiedenis. Dat is hun dagelijkse kost. Algoritmen voor begeleid machine learning zijn speciaal ontworpen om gegevens uit het verleden om te zetten in concrete voorspellingen voor de toekomst.
Het mechanisme is vrij intuïtief. Het model wordt 'getraind' door het een reeks 'gelabelde' voorbeelden te geven, waarbij het resultaat dat u interesseert al bekend is. Het algoritme analyseert deze gegevens, leert de relaties tussen de invoerkarakteristieken (bijvoorbeeld seizoensgebondenheid, promoties) en het eindresultaat (de inkomsten) herkennen en wordt zo in staat om deze kennis toe te passen op nieuwe gegevens. Dit is de kern van elke serieuze voorspellende analyse.
Deze conceptmap toont de drie grote families van algoritmen en benadrukt de centrale rol van begeleid leren bij het sturen van uw zakelijke beslissingen.
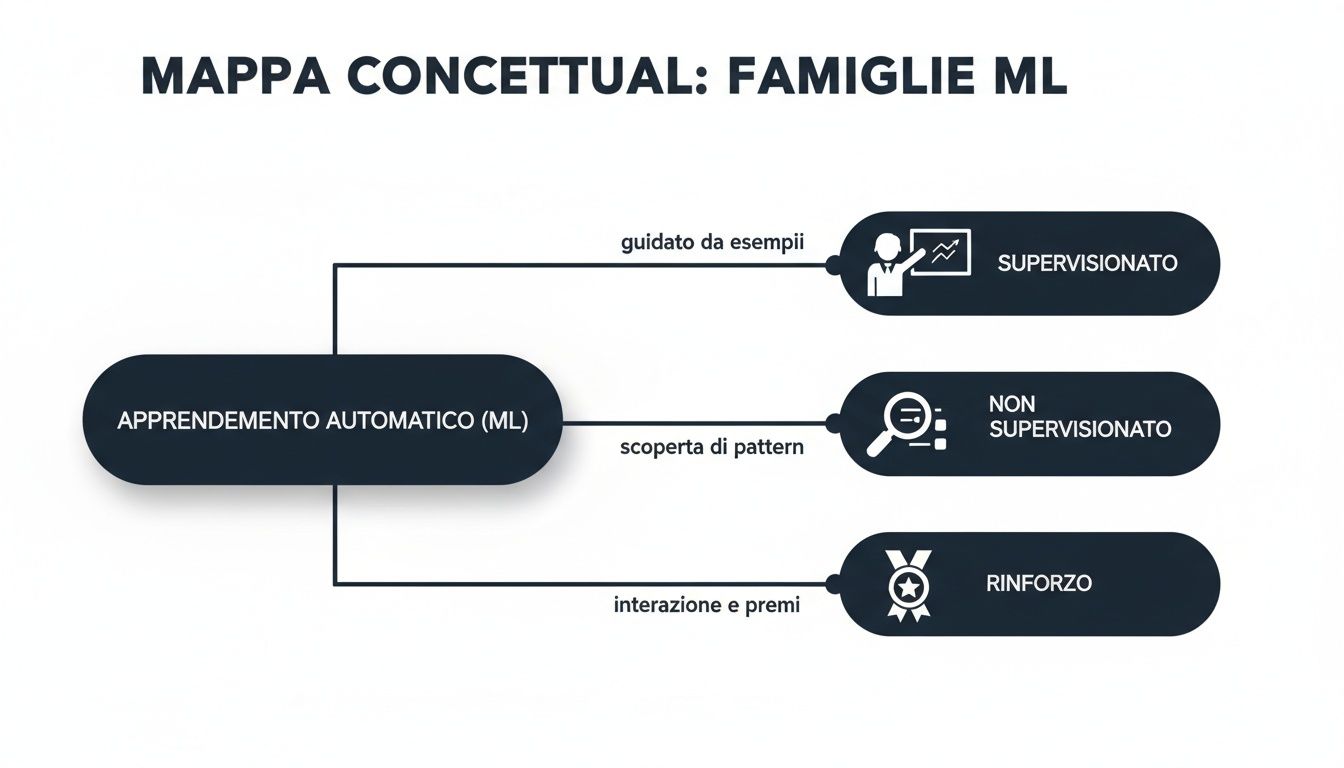
Zoals u ziet, heeft elke aanpak zijn eigen strijdtoneel, maar het is de begeleide aanpak die antwoord geeft op de voorspellende vragen die elke manager zich dagelijks stelt.
Classificatie is een van de twee fundamentele technieken van begeleid leren. Het doel ervan is niet om een getal te voorspellen, maar om een label, een categorie toe te kennen. In de praktijk beantwoordt het vragen als "ja of nee?" of "tot welke groep behoort het?".
Denk eens na over de dagelijkse uitdagingen in uw bedrijf:
In elk scenario is de impact op het bedrijf direct en meetbaar: kosten worden verlaagd, risico's worden beperkt en de efficiëntie wordt verhoogd.
De classificatie vertelt je niet alleen wat er aan de hand is, maar helpt je ook te beslissen waar je het eerst moet ingrijpen. Het is een instrument dat orde schept in de chaos en gegevens omzet in prioriteiten.
Als classificatie het antwoord geeft op de vraag 'welke categorie?', dan geeft regressie het antwoord op de vraag 'hoeveel?'. Deze techniek wordt gebruikt wanneer uw doel is om een continue numerieke waarde te voorspellen. Het is het instrument bij uitstek voor planning en strategie.
De kracht ervan ligt in het omzetten van complexe gegevens in kwantitatieve voorspellingen, die de basis vormen voor betere en weloverwogen beslissingen. Als u meer wilt weten, ontdek dan hoevoorspellende analyse gegevens omzet in succesvolle beslissingen en hoe u deze meteen in uw bedrijf kunt toepassen.
Laten we enkele concrete voorbeelden bekijken:
AI-aangedreven platforms zoals Electe ontwikkeld om deze algoritmen voor iedereen toegankelijk te maken. Je hoeft geen datawetenschapper meer te zijn om betrouwbare voorspellingen te doen. Het platform automatiseert de selectie en training van het beste model voor jouw gegevens, zodat jij je kunt concentreren op het interpreteren van de inzichten en het plannen van je volgende strategische stappen.
Wat als je gegevens kansen verbergen die je niet eens zoekt? In tegenstelling tot begeleide algoritmen, die een 'meester' nodig hebben om te leren, zijn onbegeleide algoritmen als zelfstandige detectives. Ze duiken in ruwe, ongelabelde gegevens en gaan op zoek naar verborgen structuren en verbanden.
Deze familie van machine learning-algoritmen is speciaal ontworpen om die vragen te beantwoorden waarvan je niet wist dat je ze moest stellen, en om een schijnbare chaos aan informatie om te zetten in duidelijke en winstgevende bedrijfsstrategieën.

Clustering is een van de krachtigste technieken van onbegeleid leren. Het doel is eenvoudig maar heeft een grote impact: vergelijkbare gegevens groeperen in 'clusters', oftewel homogene segmenten. In de zakenwereld vertaalt zich dit bijna altijd in een eindelijk effectieve segmentatie van het klantenbestand.
In plaats van klanten in te delen op basis van leeftijd of geografische locatie – criteria die vaak te algemeen zijn – analyseert een algoritme zoals K-Means hun daadwerkelijke koopgedrag: wat ze kopen, hoe vaak en hoeveel ze uitgeven.
Het resultaat? Klantgroepen op basis van concrete gewoonten. Hierdoor kunt u:
De impact van deze optimalisaties is niet gering. Voor kleine en middelgrote ondernemingen, die 18% van de Italiaanse AI-markt vertegenwoordigen, wordt een mogelijke vermindering van de operationele kosten tot 25% geschat dankzij dit soort analyses. Een analist kan met behulp van een platform als Electe verkoopprognoses maken met een nauwkeurigheidvan 85-90% en zich zo bevrijden van repetitieve taken. U kunt meer informatie vinden over de groei van de AI-markt in Italië en de toepassingen ervan voor het MKB.
Clustering transformeert uw klantendatabase van een eenvoudige lijst met namen naar een strategische kaart met kansen, die u precies laat zien waar u uw middelen op moet richten.
Een andere fundamentele techniek is associatieanalyse, die bekend is geworden door de 'Market Basket Analysis' (de analyse van het winkelwagentje). Deze methode ontdekt welke producten vaak samen worden gekocht, waardoor vaak verrassende correlaties aan het licht komen.
Het klassieke voorbeeld is dat van de supermarkt die ontdekt dat klanten die luiers kopen, ook vaak bier kopen. Deze informatie lijkt misschien vreemd, maar leidt tot zeer concrete strategische beslissingen.
Zo kunt u associatieanalyse in uw bedrijf gebruiken:
Deze machine learning-algoritmen vertellen je niet alleen wat je het meest verkoopt, maar leggen je ook uit hoe je klanten hun aankopen samenstellen. Met een data-analyseplatform zoals Electekunt u met een paar muisklikken deze analyses uitvoeren op uw verkoopgegevens, waardoor eenvoudige transacties worden omgezet in een onuitputtelijke bron van inzichten.
Kiezen uit de vele beschikbare machine learning-algoritmen lijkt misschien een taak voor een datawetenschapper. In werkelijkheid is het een logisch proces dat wordt gestuurd door de doelen die u wilt bereiken. De echte vraag is niet 'wat is het meest complexe algoritme?', maar 'op welke zakelijke vraag wil ik een antwoord geven?'.
Om duidelijkheid te scheppen, volstaat het om enkele belangrijke vragen te stellen. De antwoorden zullen je op natuurlijke wijze naar de algoritmenfamilie leiden die het beste bij je past, waardoor een technisch dilemma wordt omgezet in een strategische beslissing.
Voordat we naar de gegevens kijken, gaan we eerst uw doelstelling scherpstellen. Door deze drie vragen te beantwoorden, wordt het speelveld aanzienlijk kleiner.
Zodra deze punten duidelijk zijn, wordt het traject veel eenvoudiger.
Gebruik deze vragen als praktische leidraad om u te helpen bij het kiezen van het meest geschikte algoritme.
Als uw gegevens al labels of een bekend resultaat hebben, kies dan voor begeleide algoritmen zoals regressie en classificatie. Als dat niet het geval is, overweeg dan onbegeleide algoritmen zoals clustering of associatie.
Als je een continue numerieke waarde wilt voorspellen, zijn regressiealgoritmen, zoals lineaire regressie, de logische keuze. Als je daarentegen een categorie wilt voorspellen, kun je beter classificatiealgoritmen gebruiken.
Als u gegevens in niet-vooraf gedefinieerde clusters wilt groeperen, zijn algoritmen zoals K-Means geschikt. Als de groepen al vooraf bekend zijn, ga dan terug naar de classificatiealgoritmen.
Als transparantie van het model een fundamentele vereiste is, geef dan de voorkeur aan interpreteerbare modellen zoals beslissingsbomen of regressie. Als prestaties echter prioriteit hebben en transparantie minder belangrijk is, kun je gebruikmaken van 'black box'-modellen zoals neurale netwerken of gradient boosting.
Tot slot, als je over een grote hoeveelheid gegevens beschikt en maximale nauwkeurigheid nodig hebt, zijn complexe modellen zoals neurale netwerken of ensemblemethoden de meest geschikte keuze. Bij kleinere datasets of wanneer snelle training vereist is, blijven eenvoudigere modellen vaak de beste oplossing.
Deze checklist is een uitstekend uitgangspunt om te begrijpen wat u echt nodig hebt om uw gegevens om te zetten in zakelijke beslissingen.
Het goede nieuws? Je hoeft deze keuze niet alleen te maken. De ontwikkeling van data-analyseplatforms heeft het proces oneindig veel eenvoudiger gemaakt.
Het doel is vandaag de dag niet langer om experts in statistiek te worden, maar om betrouwbare voorspellingen te krijgen om het bedrijf te leiden. De technologie zorgt voor de complexiteit, jij concentreert je op de strategie.
AI-aangedreven platforms zoals Electe juist ontwikkeld om deze barrière weg te nemen. Het proces is ontwapenend in zijn eenvoud:
Op deze manier wordt voorspellende analyse democratisch. Het is niet langer voorbehouden aan datawetenschappers, maar een handig hulpmiddel voor managers, bedrijfsanalisten en ondernemers die op basis van gegevens beslissingen willen nemen, zonder ook maar één regel code te schrijven.
De theorie is fascinerend, maar het is de praktische toepassing die resultaten oplevert. Tot nu toe hebben we onderzocht wat de belangrijkste algoritmen voor machine learning zijn en hoe ze werken. Nu is het echter tijd om te kijken hoe u deze kennis kunt omzetten in een concreet concurrentievoordeel, zonder ook maar één regel code te schrijven.
Vroeger was toegang tot deze technologieën een voorrecht voor slechts enkele grote bedrijven. Tegenwoordig is deze kracht dankzij AI-aangedreven data-analyseplatforms zoals Electe eindelijk binnen het bereik van elke kmo.
Vergeet complexe programmering. Het proces om machine learning in de praktijk te brengen is ongelooflijk eenvoudig geworden en bestaat uit slechts een paar stappen, speciaal ontworpen voor mensen die zich bezighouden met zaken.
Zo werkt het:
Het belangrijkste aspect van deze aanpak is niet de technologie, maar het rendement op investering (ROI) dat deze kan genereren. Wanneer voorspellende analyses toegankelijk worden, heeft dit een impact op de hele organisatie.
Het doel is niet om managers in datawetenschappers te veranderen. Het doel is om managers de tools te geven om betere en snellere beslissingen te nemen, gebaseerd op betrouwbare voorspellingen in plaats van alleen op intuïtie.
Uw marketingteam kan klanten segmenteren met een ongekende nauwkeurigheid. De verkoopafdeling kan zich concentreren op leads met de hoogste kans op conversie. Operations-managers kunnen de voorraad optimaliseren om verspilling en kosten te verminderen. Elke beslissing wordt ondersteund door data, waardoor een eenvoudige database wordt omgezet in een motor voor groei.
Dit is wat u uit deze gids moet onthouden:
Je hebt gezien dat machine learning-algoritmen niet langer een abstract concept zijn, maar een concrete strategische troef om je bedrijf te laten groeien. Van verkoopvoorspellingen tot het optimaliseren van marketingcampagnes: de mogelijkheden om data om te zetten in winst zijn enorm en, bovenal, binnen handbereik. Het tijdperk waarin alleen grote bedrijven zich geavanceerde analyses konden veroorloven, is voorbij.
Met tools zoals Electe kun je eindelijk stoppen met op goed geluk te navigeren en beslissingen nemen op basis van nauwkeurige voorspellingen. Je hoeft niet te investeren in een team van datawetenschappers of complexe IT-projecten. Het enige wat je nodig hebt, is de bereidheid om op een nieuwe manier naar je gegevens te kijken om de toekomst van je bedrijf te verhelderen.
Klaar om de eerste stap te zetten?
Ontdek hoe Electe werkt Electe start uw gratis proefperiode →

.svg)
.svg)
.svg)



.png)

